

‘Photo Wake-Up’ Is A Freaky New Technique For Creating 3D Animation From A Single Still Image
Researchers at the University of Washington have developed a new technique for creating 3d cg animation from a single photo. They’re calling it “Photo Wake-Up” and the demo video above gives a clear idea of what can be accomplished with the technique. The Photo Wake-Up research was supported by Facebook, Google, Huawei, and a Reality Lab Huawei Fellowship.
The technique is demonstrated by using a variety of single-image inputs, including photographs, realistic illustrations, cartoon drawings, and abstracted human forms. The figures are animated in various ways, such as walking toward the screen, running, sitting, and jumping.
In a paper that details the process (download PDF), the researchers —
Chung-Yi Weng, Brian Curless, and Ira Kemelmacher-Shlizerman — explain that a lot of the technical development required to do this already exists. Those existing techniques include segmenting a person from an image, 2d skeleton estimating, and fitting a morphable, posable 3d model into the still image. The UofW researchers have built on that previous research by attempting to have the animated figures conform more closely to the 2d silhouettes and to create more natural looking characters.
The key technical advance of Photo Wake-Up is creating an animatable 3d model that matches the silhouette of a single photo and handles self-occlusion. “Rather than deforming the 3d mesh from the first stage – a difficult problem for intricate regions such as fingers and for scenarios like abstract artwork – we map the problem to 2d, perform a silhouette-aligning warp in image space, and then lift the result back into 3d,” the researchers explained. “This 2d warping approach works well for handling complex silhouettes. Further, by introducing label maps that delineate the boundaries between body parts, we extend our method to handle certain self-occlusions.”
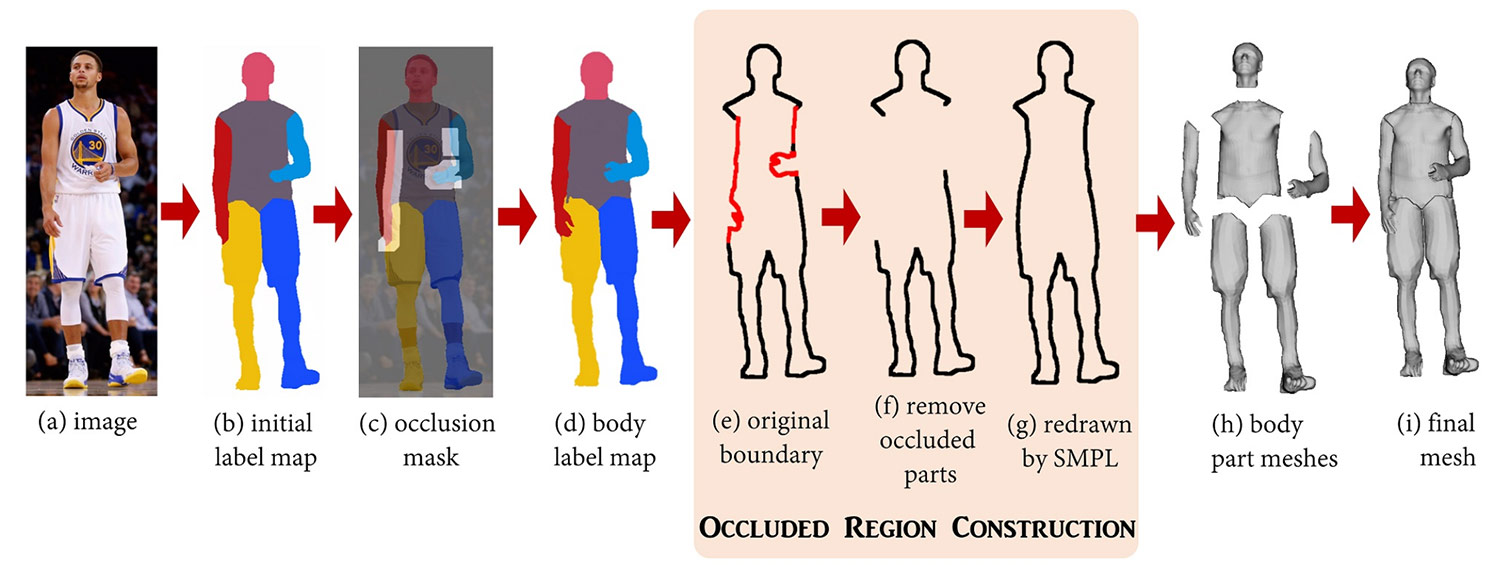
In the image above, the researchers show how the occlusion works. Starting from the input image (a) and its corresponding silhouette and projected SMPL body part model, they recover an initial body part label map (b). After identifying points at occlusion boundaries, they construct an occlusion mask (lighter
areas in (c) and then refine it to construct the final body label map (d). The body part regions near occlusions have spurious boundaries, shown in red in (e). Those spurious boundaries (f) are removed, and replaced with transformed versions of the SMPL boundaries (g). They can then reconstruct the body part-by-part (h) and assemble into the final mesh (i).
The occlusion fits into this broader production pipeline:
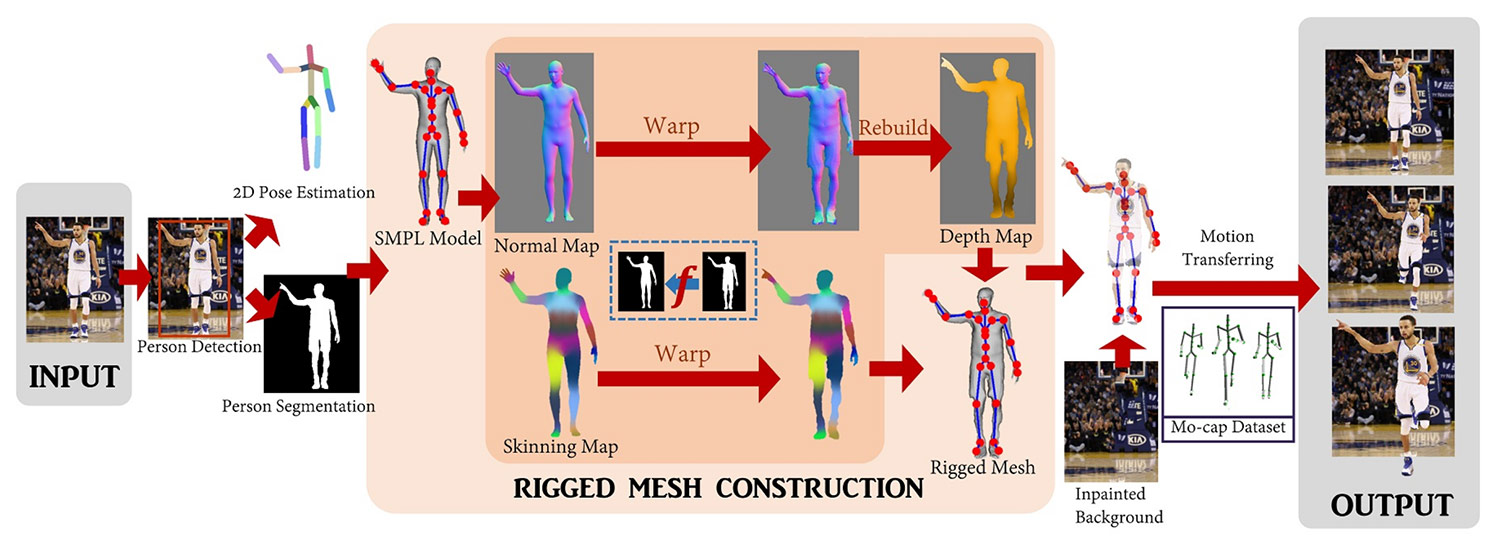
The creators of the technique point out that the 3d animation can be used in augmented or virtual reality experiences, so it’s easy to envision the potential application of such technology in gaming and educational contexts, as well as site-specific works, such as bringing a piece of art to life in a museum. The researchers “believe the method not only enables new ways for people to enjoy and interact with photos, but also suggests a pathway to reconstructing a virtual avatar from a single image while providing insight into the state of the art of human modeling from a single photo.”
It’s important to note that there is currently a lot of complementary research being done in automated recreations of photorealistic cg imagery and naturalistic movement — for example, here and here. If it all seems a bit crude at this point, just remember that much of the technology in current cg and vfx software also started out as quirky research projects in a computer science lab. And when these technologies evolve to a higher standard and people start creating believable animation of humans from still images, it will give rise to all kinds of ethical quandaries that none of these scientists seem particularly interested in acknowledging or considering as part of their research practice.